A new kind of forecasting tournament
Ben Day & Toby Shevlane in collaboration with others at Mantic

In brief
Mantic is creating a new kind of tournament to probe the frontier of AI forecasting. Participants will compete to write forecasting questions that the best AI forecasting systems disagree on; the greater the disagreement, the greater the cash prize. There is a $25,000 USD prize pool for question-writers.
We are looking for question-writers and AI forecasters to take part.
If you are interested in being a question-writer applyhere.If you are interested in entering an AI forecaster applyhere.
Applications are now closed.
In detail
Motivation
AI forecasting systems have improved significantly over the last few years, in part thanks to tournaments like the Metaculus FutureEval series. We think the most valuable resource that these tournaments provide is information about where further progress can be made, and this comes from seeing where the leading systems disagree. Because the forecasts include explanations, we can reason about which system was right in a particular disagreement.
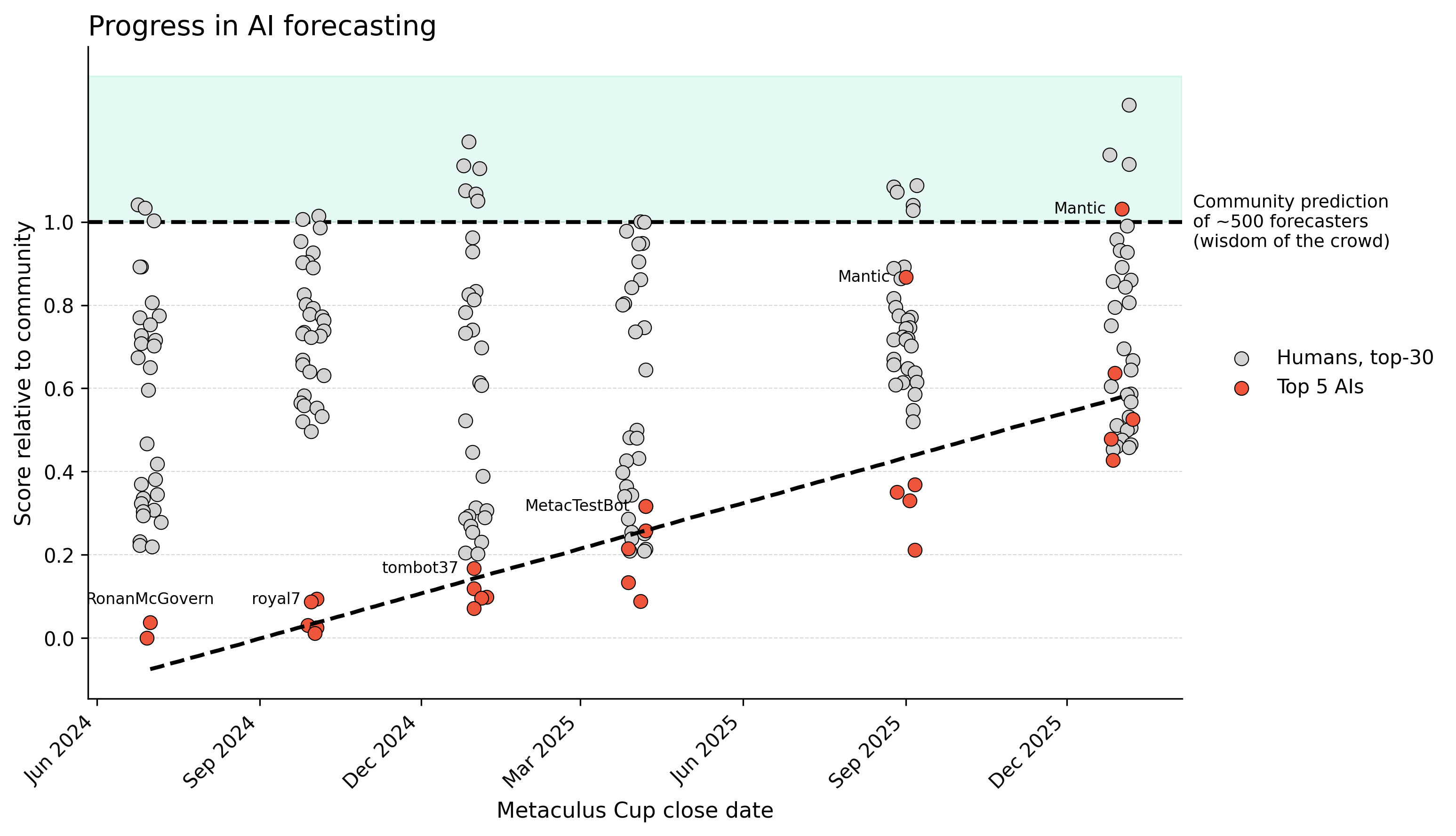
At Mantic we think a lot about the problem of detecting whether a particular forecasting question was ‘hard’ or ‘impossible’. In both cases, your system scores badly. The distinction is whether there was anything you could have reasonably done to improve your forecast. In the impossible case, there wasn’t; in the hard case, there was. Detecting the difference in general is likely equivalent to solving forecasting. Detecting the difference for a specific case only requires that a different forecasting system disagrees with you and can explain why.
What we’re talking about here is the difference between aleatoric and epistemic uncertainty. Aleatoric uncertainty is the irreducible uncertainty that comes from randomness in a system, epistemic uncertainty comes from your lack of understanding of the system. No matter how well you study a fair coin, your uncertainty about the result of a flip stays the same, and that is the aleatoric uncertainty.
Where do the best forecasters disagree? The Goldilocks zone.
Until recently, disagreement between AI systems was dominated by simple errors in understanding or reasoning. However, as these systems have approached human-level forecasting, their disagreements have become more interesting: they reveal divergent models of the world or differences in their ability to gather relevant information, i.e. the differences in their epistemic uncertainty.
Unfortunately, most tournament questions do not probe these differences. Forecasters agree on both solved questions, where all that remains is the irreducible aleatoric uncertainty, and questions where no system has been able to make relative progress in reducing their epistemic uncertainty. Between these is the Goldilocks zone where there is some variation in the degree of understanding.
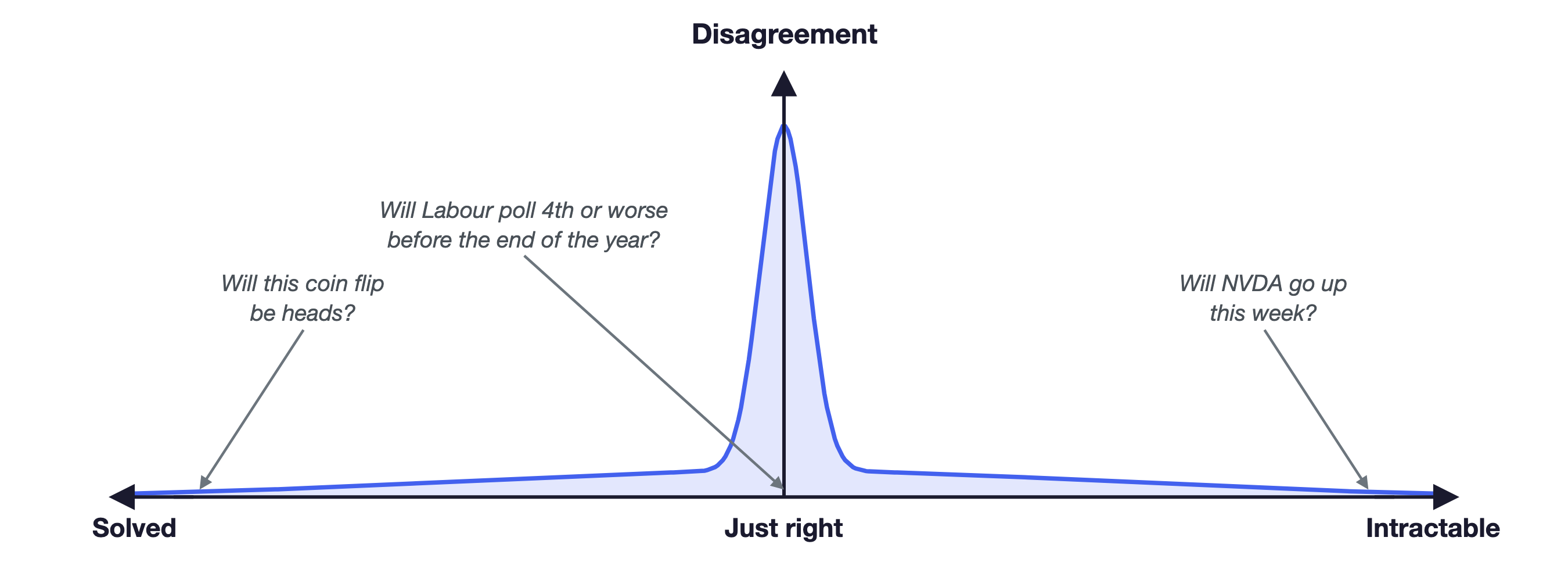
We think targeting the Goldilocks zone is likely to be well-aligned with pursuing high value-of-information (VOI) questions. Far from the Goldilocks zone, the forecasters add very little information, either because they make no progress or because the problem is already solved.
Core idea
Given that the level of disagreement between top forecasters determines how useful a tournament is for making progress, we think we should try optimising for disagreement. The dual tournament sets up a feedback loop that drives progress by incentivising the question-writers to discover weaknesses in the forecasters, which the forecasters are incentivised to patch. This keeps the focus tightly tracking the frontier and makes the tournament as effective as possible.
Similar dynamics are present in interspecies competition, curriculum learning, and improving security via simulated adversarial attacks or red teaming.
Tournament structure
The tournament will run for four months from the middle of April to the middle of August and there will be around 500 questions in total with some front loading of questions. We’re looking to recruit up to 50 question-writers and 20 forecasters.
All questions and forecasts will be made publicly available. Leaderboards for both question-writing and forecasting will be publicly accessible throughout the tournament. This includes the specific questions, forecasts, resolutions, and the results of any appeals.
For forecasters
The forecasting component will follow the structure used in Metaculus AI competitions for the basics: questions will be released without warning around the clock, competitors will have an hour to submit their forecast, and spot peer scoring will be used. There will be ~no changes from the Metaculus API, so if your system is set up to participate in Metaculus tournaments then you will only need to change the base URL to forecast in this tournament.
Nonprofessional forecasters will have their costs subsidised at $2 per forecast. A prize pool of up to $5,000 will also be distributed based on the final standings.1
Questions will be resolved automatically by LLM judges and competitors will have the option to appeal to a panel of human judges if they believe there has been an error. The panel will be selected from the question-writers and announced ahead of the start of the competition.
For question-writers
Each question-writer will be allocated a budget of questions and given access to a question submission flow that includes AI assistants to help refine and improve their questions. Questions will be automatically screened for general suitability to avoid trivial or ambiguous questions. Submitted questions will be queued for forecasting by the AI systems and once the forecasting is complete, questions will be scored based on the degree of disagreement between the forecasters. This means question writers will get fast feedback on the quality of their submissions and the question-writing leaderboard will be live-updating. See our technical appendix for more detail on the scoring methodology.
The maximum disagreement score that can be achieved is a little less than 500 points and we will pay $10 for every 100 points. Any prize money that remains at the end of the tournament will be distributed in proportion to the final leaderboard standings.
Applying
We are looking for question-writers and AI forecasters to take part.
If you are interested in being a question-writer apply here.
If you are interested in entering an AI forecaster apply here.
$250 per forecaster up to 20 forecasters for a maximum of $5,000. For example, if 10 forecasters enter, the pool will be $2,500.
Hi Ben and Toby, I love the structure of this!
We wanted to do something similar while I was at Metaculus, but never managed to.
I'm excited that you're doing this.